publications
* denotes equal contribution
An up-to-date list is available on Google Scholar.
2024
-
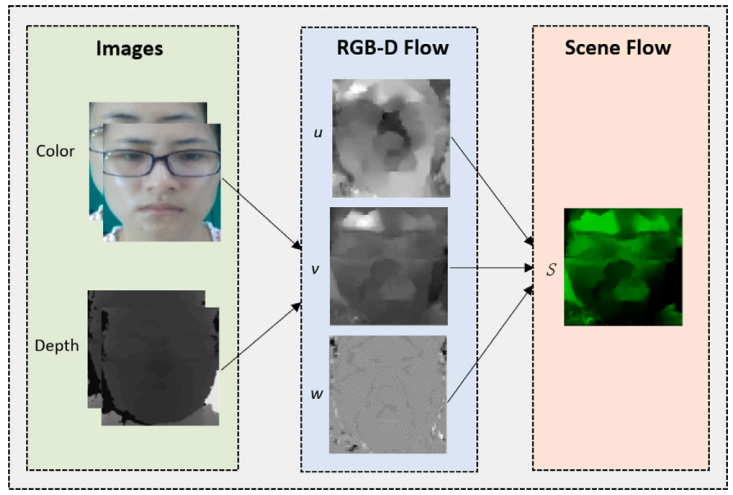 ×SFAMNet: A Scene Flow Attention-based Micro-expression NetworkGen-Bing Liong, Sze-Teng Liong, Chee Seng Chan, and John SeeNeurocomputing, 2024
×SFAMNet: A Scene Flow Attention-based Micro-expression NetworkGen-Bing Liong, Sze-Teng Liong, Chee Seng Chan, and John SeeNeurocomputing, 2024Tremendous progress has been made in facial Micro-Expression (ME) spotting and recognition; however, most works have focused on either spotting or recognition tasks on the 2D videos. Until recently, the estimation of the 3D motion field (a.k.a scene flow) for the ME has only become possible after the release of the multi-modal ME dataset. In this paper, we propose the first Scene Flow Attention-based Micro-expression Network, namely SFAMNet. It takes the scene flow computed using the RGB-D flow algorithm as the input and predicts the spotting confidence score and emotion labels. Specifically, SFAMNet is an attention-based end-to-end multi-stream multi-task network devised to spot and recognize the ME. Besides that, we present a data augmentation strategy to alleviate the small sample size problem during network learning. Extensive experiments are performed on three tasks: (i) ME spotting; (ii) ME recognition; and (iii) ME analysis on the multi-modal CAS(ME)^3 dataset. Empirical results indicate that depth is vital in capturing the ME information and the effectiveness of the proposed approach. Our source code is publicly available at https://github.com/genbing99/SFAMNet.
2023
-
 ×Doing More With Moiré Pattern Detection in Digital PhotosCong Yang, Zhenyu Yang, Yan Ke, Tao Chen, Marcin Grzegorzek, and John SeeIEEE Transactions on Image Processing, 2023
×Doing More With Moiré Pattern Detection in Digital PhotosCong Yang, Zhenyu Yang, Yan Ke, Tao Chen, Marcin Grzegorzek, and John SeeIEEE Transactions on Image Processing, 2023Detecting moiré patterns in digital photographs is meaningful as it provides priors towards image quality evaluation and demoiréing tasks. In this paper, we present a simple yet efficient framework to extract moiré edge maps from images with moiré patterns. The framework includes a strategy for training triplet (natural image, moiré layer, and their synthetic mixture) generation, and a Moiré Pattern Detection Neural Network (MoireDet) for moiré edge map estimation. This strategy ensures consistent pixel-level alignments during training, accommodating characteristics of a diverse set of camera-captured screen images and real-world moiré patterns from natural images. The design of three encoders in MoireDet exploits both high-level contextual and low-level structural features of various moiré patterns. Through comprehensive experiments, we demonstrate the advantages of MoireDet: better identification precision of moiré images on two datasets, and a marked improvement over state-of-the-art demoiréing methods.
-
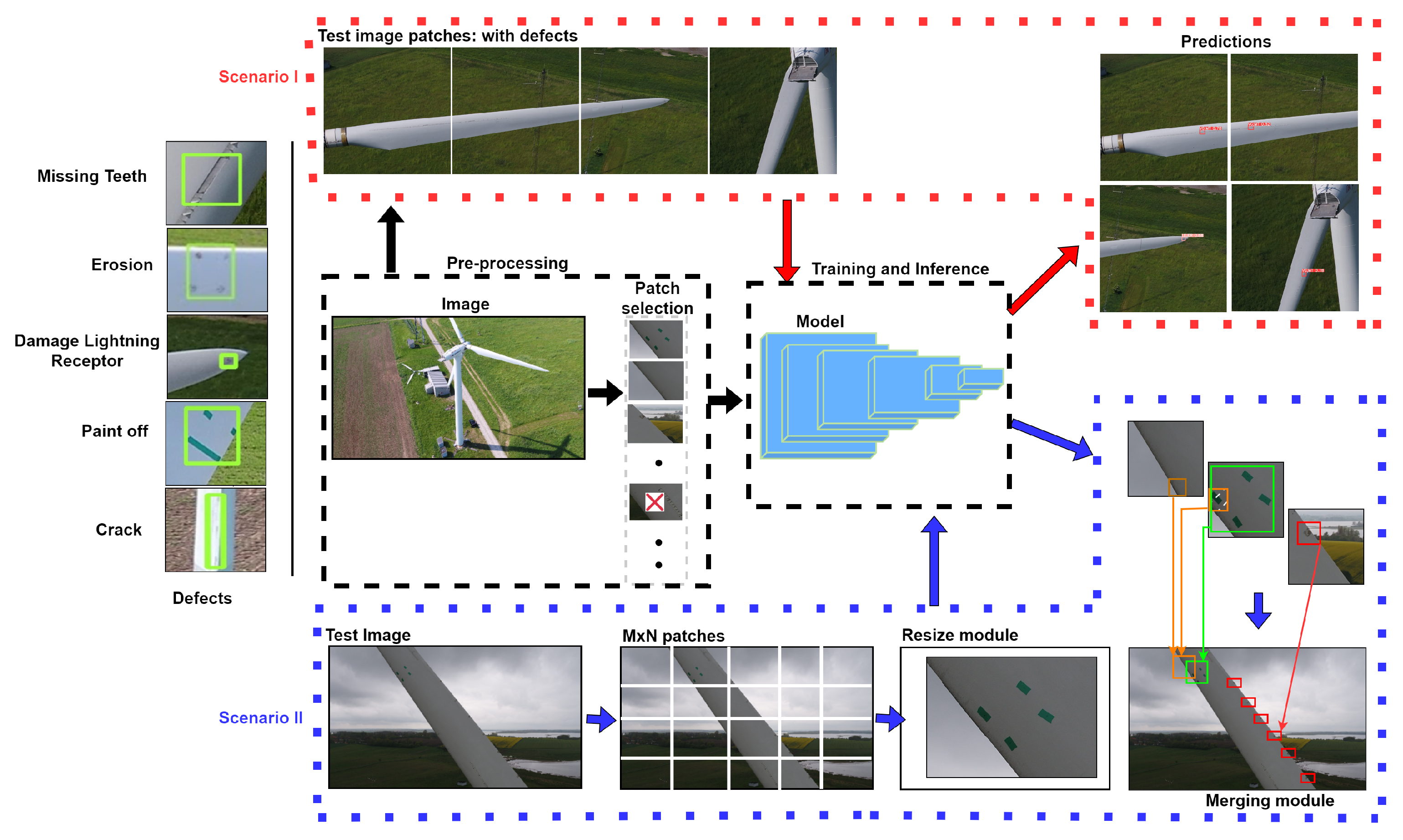 ×Slice-Aided Defect Detection in Ultra High-Resolution Wind Turbine Blade ImagesImad Gohar, Abderrahim Halimi, John See, Weng Kean Yew, and Cong YangMachines, 2023
×Slice-Aided Defect Detection in Ultra High-Resolution Wind Turbine Blade ImagesImad Gohar, Abderrahim Halimi, John See, Weng Kean Yew, and Cong YangMachines, 2023The processing of aerial images taken by drones is a challenging task due to their high resolution and the presence of small objects. The scale of the objects varies diversely depending on the position of the drone, which can result in loss of information or increased difficulty in detecting small objects. To address this issue, images are either randomly cropped or divided into small patches before training and inference. This paper proposes a defect detection framework that harnesses the advantages of slice-aided inference for small and medium-size damage on the surface of wind turbine blades. This framework enables the comparison of different slicing strategies, including a conventional patch division strategy and a more recent slice-aided hyper-inference, on several state-of-the-art deep neural network baselines for the detection of surface defects in wind turbine blade images. Our experiments provide extensive empirical results, highlighting the benefits of using the slice-aided strategy and the significant improvements made by these networks on an ultra high-resolution drone image dataset.
-
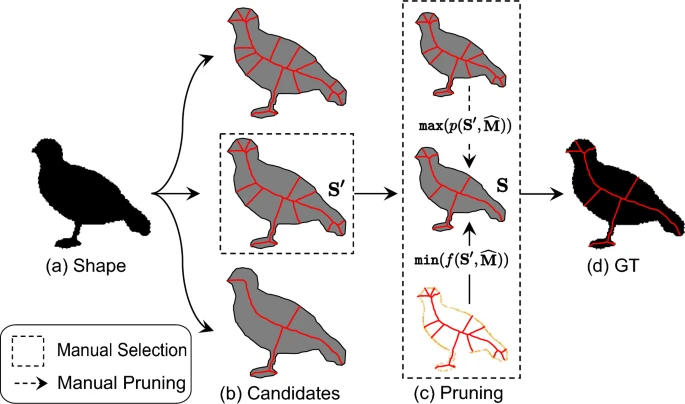 ×Skeleton Ground Truth Extraction: Methodology, Annotation Tool and BenchmarksCong Yang, Bipin Indurkhya, John See, Bo Gao, Yan Ke, Zeyd Boukhers, Zhenyu Yang, and Marcin GrzegorzekInternational Journal of Computer Vision, 2023
×Skeleton Ground Truth Extraction: Methodology, Annotation Tool and BenchmarksCong Yang, Bipin Indurkhya, John See, Bo Gao, Yan Ke, Zeyd Boukhers, Zhenyu Yang, and Marcin GrzegorzekInternational Journal of Computer Vision, 2023Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN), but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target’s context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
-
 ×ERNet: An Efficient and Reliable Human-Object Interaction Detection NetworkJunYi Lim, Vishnu Monn Baskaran, Joanne Mun-Yee Lim, KokSheik Wong, John See, and Massimo TistarelliIEEE Transactions on Image Processing, 2023
×ERNet: An Efficient and Reliable Human-Object Interaction Detection NetworkJunYi Lim, Vishnu Monn Baskaran, Joanne Mun-Yee Lim, KokSheik Wong, John See, and Massimo TistarelliIEEE Transactions on Image Processing, 2023Human-Object Interaction (HOI) detection recognizes how persons interact with objects, which is advantageous in autonomous systems such as self-driving vehicles and collaborative robots. However, current HOI detectors are often plagued by model inefficiency and unreliability when making a prediction, which consequently limits its potential for real-world scenarios. In this paper, we address these challenges by proposing ERNet, an end-to-end trainable convolutional-transformer network for HOI detection. The proposed model employs an efficient multi-scale deformable attention to effectively capture vital HOI features. We also put forward a novel detection attention module to adaptively generate semantically rich instance and interaction tokens. These tokens undergo pre-emptive detections to produce initial region and vector proposals that also serve as queries which enhances the feature refinement process in the transformer decoders. Several impactful enhancements are also applied to improve the HOI representation learning. Additionally, we utilize a predictive uncertainty estimation framework in the instance and interaction classification heads to quantify the uncertainty behind each prediction. By doing so, we can accurately and reliably predict HOIs even under challenging scenarios. Experiment results on the HICO-Det, V-COCO, and HOI-A datasets demonstrate that the proposed model achieves state-of-the-art performance in detection accuracy and training efficiency. Codes are publicly available at https://github.com/Monash-CyPhi-AI-Research-Lab/ernet.
-
 ×MEGC2023: ACM Multimedia 2023 ME Grand ChallengeAdrian K Davison, Jingting Li, Moi Hoon Yap, John See, Wen-Huang Cheng, Xiaobai Li, Xiaopeng Hong, and Su-Jing WangIn Proceedings of the 31st ACM International Conference on Multimedia, 2023
×MEGC2023: ACM Multimedia 2023 ME Grand ChallengeAdrian K Davison, Jingting Li, Moi Hoon Yap, John See, Wen-Huang Cheng, Xiaobai Li, Xiaopeng Hong, and Su-Jing WangIn Proceedings of the 31st ACM International Conference on Multimedia, 2023Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. Unfortunately, the small sample problem severely limits the automation of ME analysis. Furthermore, due to the weak and transient nature of MEs, it is difficult for models to distinguish it from other types of facial actions. Therefore, ME in long videos is a challenging task, and the current performance cannot meet the practical application requirements. Addressing these issues, this challenge focuses on ME and the macro-expression (MaE) spotting task. This year, in order to evaluate algorithms’ performance more fairly, based on CAS(ME)2, SAMM Long Videos, SMIC-E-long, CAS(ME)3 and 4DME, we build an unseen cross-cultural long-video test set. All participating algorithms are required to run on this test set and submit their results on a leaderboard with a baseline result.
2022
-
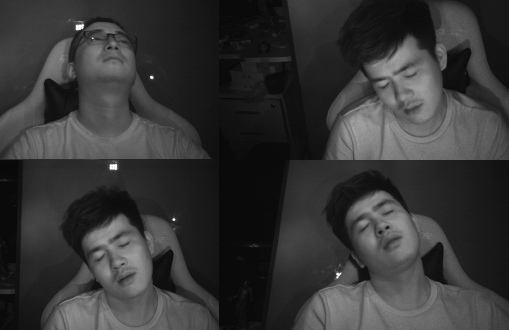 ×FatigueView: A Multi-Camera Video Dataset for Vision-Based Drowsiness DetectionCong Yang, Zhenyu Yang, Weiyu Li, and John SeeIEEE Transactions on Intelligent Transportation Systems, 2022
×FatigueView: A Multi-Camera Video Dataset for Vision-Based Drowsiness DetectionCong Yang, Zhenyu Yang, Weiyu Li, and John SeeIEEE Transactions on Intelligent Transportation Systems, 2022Although vision-based drowsiness detection approaches have achieved great success on empirically organized datasets, it remains far from being satisfactory for deployment in practice. One crucial issue lies in the scarcity and lack of datasets that represent the actual challenges in real-world applications, e.g. tremendous variation and aggregation of visual signs, challenges brought on by different camera positions and camera types. To promote research in this field, we introduce a new large-scale dataset, FatigueView, that is collected by both RGB and infrared (IR) cameras from five different positions. It contains real sleepy driving videos and various visual signs of drowsiness from subtle to obvious, e.g. with 17,403 different yawning sets totaling more than 124 million frames, far more than recent actively used datasets. We also provide hierarchical annotations for each video, ranging from spatial face landmarks and visual signs to temporal drowsiness locations and levels to meet different research requirements. We structurally evaluate representative methods to build viable baselines. With FatigueView, we would like to encourage the community to adapt computer vision models to address practical real-world concerns, particularly the challenges posed by this dataset.